🛳️ Deployment
Our goal is to keep an isolated environment for testing out new features before pushing it to production.
This is called as blue-green deployment. See more here.
❄️ Snowflake
🟦🟩 Blue/green deployment
References:
⚠️ Warning! If you want to keep using incremental build, go with production rollback 👇 instead!
As former production tables get demoted to staging via the swap feature, the next incremental load will build on top of obsolete tables in staging before swapping.
Imagine:
- T: Imagine that our run fully refreshes the data in staging, then swaps it with the production database in T-1
- T+1: A new production cycle is due, but only certain data sources have to be processed again, so you decide to go with an incremental refresh.
- T+1: You then wonder why all the information we updated in T is missing?
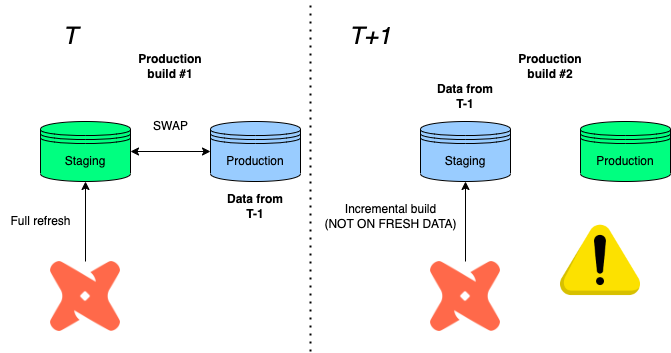
Well, since we built on top of a production data in T-1 before swapping again, the information loss is the difference between staging and production in T!
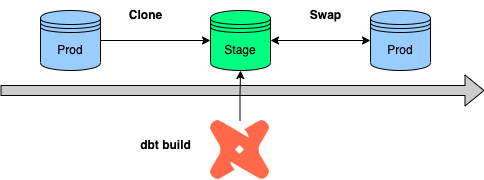
🧻 Production rollback
Instead of swapping databases, (1) we copy the previous production data to a staging environment, (2) rebuild the tables under scope, then (3) clone it back to production.
This also works with incremental models, because we always clone back the latest production loading before building on top of it.
🔍 BigQuery
Unfortunately, swapping is only available in Snowflake, so the idea is to run & test all models before loading it to the production environment instead.
This is called WAP (Write-Audit-Publish). Read more about this here.
BigQuery is not able to able to rename datasets, therefore, swapping by renaming with subsequent commits is ruled out.
WAP (Write-Audit-Publish)
This is a classical approach mentioned by the deck linked above.
- Builds all in an audit staging dataset
- Then, build only top level models under the activation (BI) layer in prod again.
- Traffic is stopped if the build failed in the audit environment.

Here's the macro to implement it:
{% macro generate_schema_name_for_env(custom_schema_name=none) -%}
{%- set default_schema = target.schema -%}
{%- if custom_schema_name is not none -%}
{%- if custom_schema_name not in ("staging", "intermediate") and
"audit" in target.name -%}
unaudited
{%- else -%}
{{ custom_schema_name | trim }}
{%- endif -%}
{%- else -%}
{{ default_schema }}
{%- endif -%}
{%- endmacro %}
{% macro generate_schema_name(schema_name, node) -%}
{{ generate_schema_name_for_env(schema_name) }}
{%- endmacro %
Add tags to mart (top) layer (or separate folder structure)
models:
mart:
+tags: ['mart']
dbt Cloud job
#build it in an audit dataset
dbt run --target prod_audit
dbt test --target prod_audit
#recreate top-layer in production with tags
dbt run --target prod -s tag:mart
#or with path
dbt run --target prod -s mart.*
WAC (Write-Audit-Clone)
One thing which helps us move forward is that BigQuery also has now a Table Clone feature.
What we can do is to use the production job to load to the data to a new dataset e.g. analytics_stage and clone the top-level tables with the mart tag to analytics_prod.

Please do review the code below before copy-pasting as it can be specific to a use-case!
{% macro has_intersect(set1, set2) %}
--check if the two sets have intersection
{% for item in set1 %}
{% if item in set2 %}
{{ return(True) }}
{% endif %}
{% endfor %}
{{ return(False) }}
{% endmacro %}
{% macro write_audit_publish() %}
{#
EXPECTED BEHAVIOR:
1. Loads every table to a single dataset (this requires using a different target name than 'prod')
2. Gatheres all the model/table names maching with the supplied tags
3. We redistribute the tables to the correct datasets in production depending on the tag (=dataset)
#}
{% if target.name == 'staging' %}
{{ dbt_utils.log_info("Gathering tables to clone from...") }}
{% set tables = dict() %}
{% set tags_to_clone = var('tags_to_clone') %}
-- create empty dictionary for table-tag mapping
{% for model in graph.nodes.values() %}
-- clone only intersectrions and tables
{%- if has_intersect(tags_to_clone, model.tags) and model.config.materialized == 'table' %}
{% if model.schema not in tables.keys() %}
{% do tables.update({model.tags: []}) %}
{% endif %}
{% do tables[model.tags].append(model.name) %}
{% endif %}
{% endfor %}
{{ dbt_utils.log_info("Cloning in progress...") }}
-- iterate through all the tables and clone them over to chosen destination
{% for key, value in tables.items() %}
-- create prod schema if not exists
{% set sql -%}
create schema if not exists {{ key }};
{%- endset %}
{% do run_query(sql) %}
{% for item in value %}
{% call statement(name, fetch_result=true) %}
-- copy from single analytics_staging schema but distribute to different schemas in prod
create or replace table
{{ target.project }}.{{ key }}.{{ item }}
clone {{ target.project }}.{{ target.dataset }}.{{ item }};
{% endcall %}
{% endfor %}
{{ dbt_utils.log_info("Tables cloned successfully!") }}
{% endfor %}
{% else %}
{{ dbt_utils.log_info("WAP is only supported on staging! Process skipped...") }}
{% endif %}
{% endmacro %}
Cloned tags are driven by the tags_to_clone variable:
vars:
tags_to_clone: ['mart', 'utils']
Then in dbt Cloud, the process would be:
- builds all in the staging (pre-prod) dataset
- copies all tables over to prod with the macro
#build it in analytics_staging
dbt seed
dbt run
dbt test
#copy mart layer to analytics
dbt run-operation write_audit_publish
Limitations:
- We can’t copy views — no problem because we don’t have those
- Additional storage cost incurred on the difference between clones and source tables
🪞 Mirror Layer
Time and time again, we stumble into data integration issues because we are still dependent on third-party data submissions. Put simply, if source shares/servers are not live, we are not able to run our end-to-end jobs or certain tables are empty.
Another way to overcome that is instead of creating is that we create a layer at the bottom just before staging.
Structurally, the project would be extended with a raw layer which copies the source tables 1:1:

with source as (
select * from {{ source('name', 'table') }}
),
This layer then would be separated from the dev/production main build job and refreshed manually when needed.
dbt Cloud job:
#build it from staging
dbt build staging.*+